Cards
Units of orientation about the repository: subsystem, file, symbol, boundary, workflow, or invariant.
Repository Orientation Infrastructure
Repository orientation for AI coding systems.
Most AI coding systems still behave like first-time visitors in unfamiliar repositories. Mímir maintains repository world-state and brokers bounded rehydration through a deterministic interface so the model can ask where to start, what is adjacent, and when to stop widening.
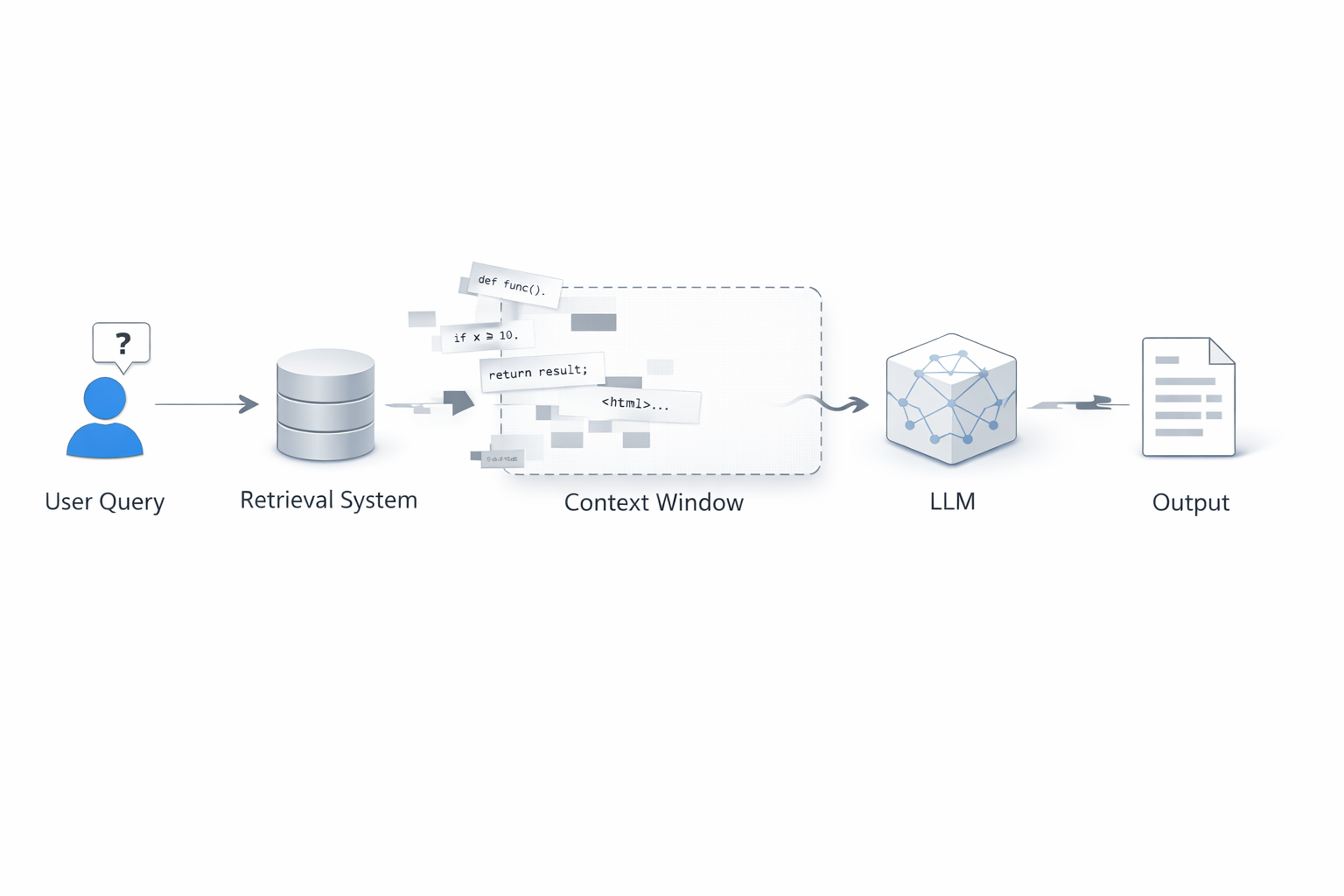
The Problem
The deeper failure is not bad code in isolation. It is the appearance of understanding before the system is actually oriented. Search, retrieval, and larger context windows still begin from the same disadvantage: reconstructing the repository from fragments instead of starting from a durable sense of what owns the behavior and what boundaries sit nearby.
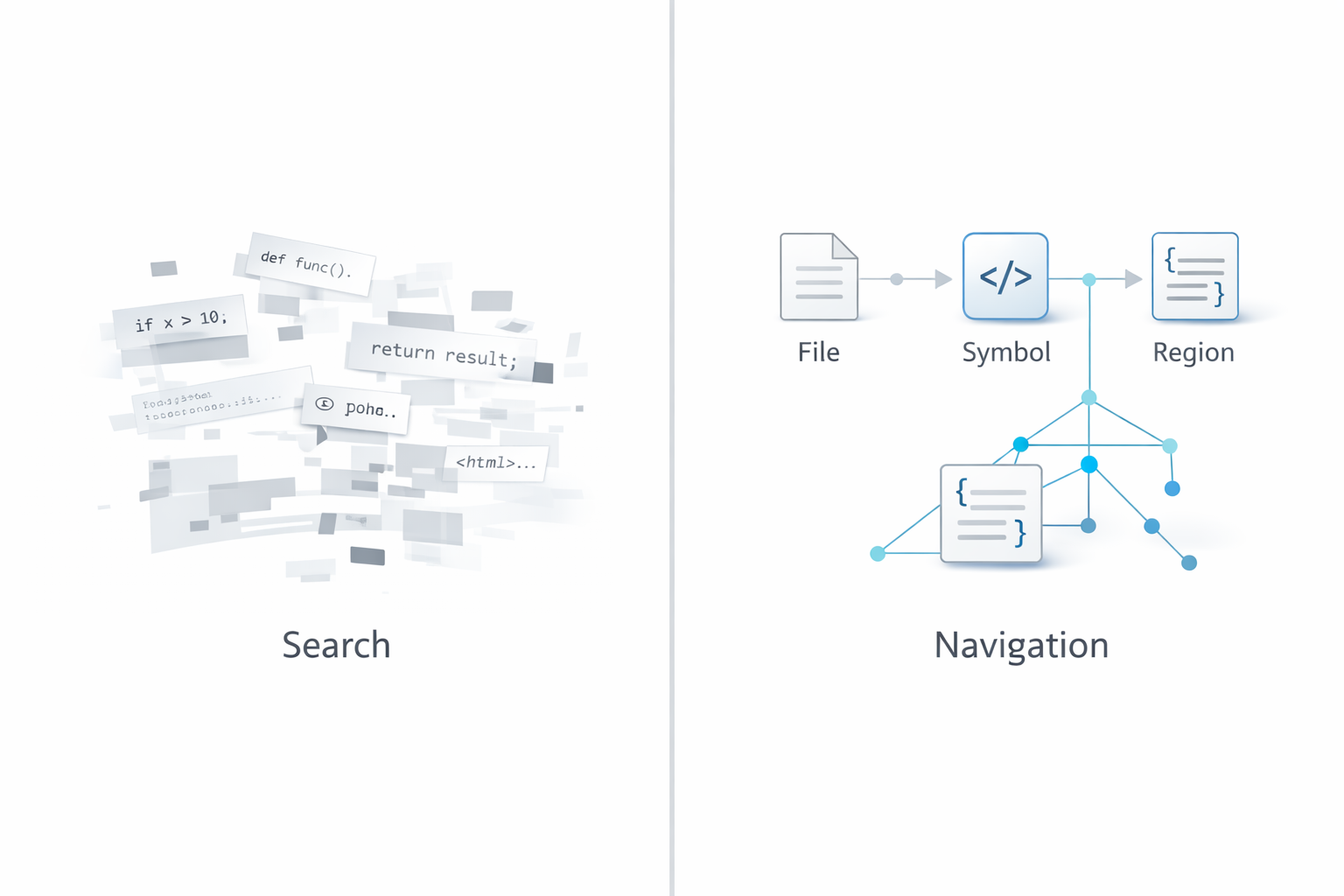
What Mímir Changes
Mímir is a persistent repository self-model. It maintains world-state and brokers bounded context from likely subsystem to likely file to likely symbol. The shift is from "find similar text" to "start from an oriented map of the codebase."

Mímir is a GPS for a codebase, not a search engine.
Units of orientation about the repository: subsystem, file, symbol, boundary, workflow, or invariant.
Links that keep orientation stable as code moves, is renamed, or is partially rewritten.
Evidence that shapes confidence through structure, traces, edit history, retrieval success, and verified outcomes.
Relationships that reveal what is nearby, upstream, downstream, dependent, or risky to touch in the system.
How It Works In Practice
Mímir does not just store structure; it serves it through a brokered boundary between the model and world-state services. The model asks in explicit modes and receives either a bounded rehydration bundle with sources, adjacencies, and confidence or a disciplined abstention when widening would add noise. The boundary is deterministic and inspectable, creating a measurable eval surface instead of opaque prompt stuffing.
Unit of delivery: a bounded rehydration bundle.
Current State
Mímir has moved beyond thesis stage: the world-state substrate is implemented, the brokered interface layer is live, and the system has been exercised across real repositories. In those runs, brokered orientation usually finds the right place to begin; most misses now come from widening and abstention policy.
Focus now: policy-governed widening, disciplined abstention, throughput, and generalization.
Why This Matters
This is not just better search. It is an operating model for large, stale, unfamiliar, recently changed, or messy repositories: bounded working sets, better first-target selection, disciplined widening, and honest abstention when extra context would make outcomes worse.
Less context budget spent reconstructing orientation before useful work begins.
Agents get pointed at the right subsystem, file, and symbol earlier in the task.
Bounded working sets and honest abstention reduce failures caused by noisy widening.
Who This Is For
Builders who want to take orientation infrastructure from sharp system to durable product.
Leaders working on code navigation, search, and agent surfaces who see orientation as the missing layer.
People who can harden brokered context into a reliable service boundary.
Partners who understand how to position a foundational layer inside the AI coding stack.
Closing
I'm looking for technical, product, and strategic conversations with people who want repository orientation treated as durable infrastructure, not a one-off feature.